Parallel Computing
Parallel computing can be defined as a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently. The primary goal of parallel computing is to improve the speed of computation. Parallel computing can also be defined as the simultaneous use of multiple computing resources (cores or computers) to perform a concurrent calculation where large problems are broken down into smaller ones and each smaller one is solved concurrently on different computing resources. Parallel computing involves 2 distinct areas of computing technologies:
- Computer Architecture (Hardware Aspect): Focus on supporting parallelism at an architectural level
- Parallel Programming (Software Aspect): Focuses on solving problem concurrently by fully using the computational power
In order to execute parallel programming, the hardware must provide a support to run concurrent executions of multiple processes or multiple threads. Most of the modern process implements the Harvard architecture which consists of the 3 main components:
- Memory (instruction memory and data memory)
- Central Processing Unit (control unit and arithmetic logic unit)
- Input Output Interfaces
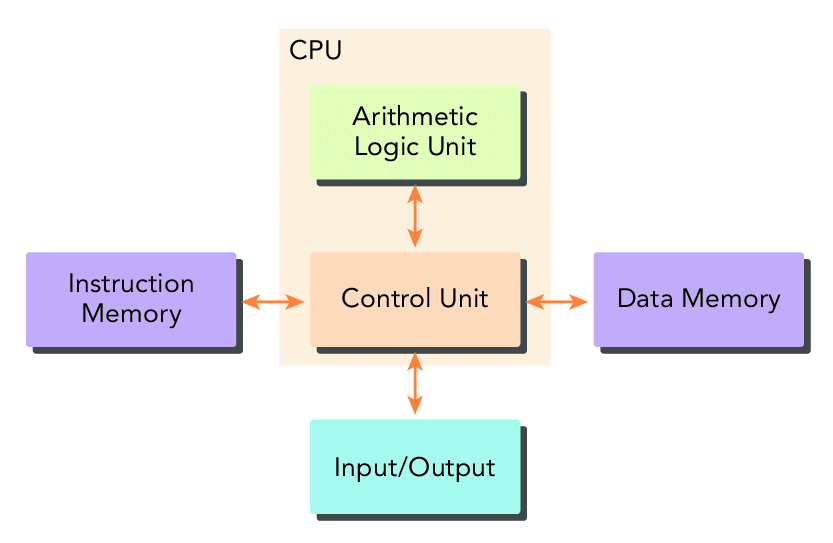
The key of HPC is Central Processing Unit AKA core. In the past days, there was only one core in the chip (uni-processor architecture) but at the current multiple cores are integrated into the single processor (multicore) which can support parallelism at an architectural level.
Sequential and Parallel Programming
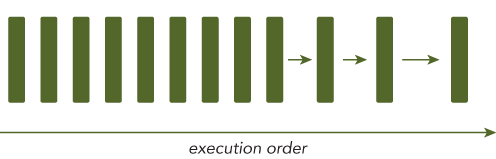
Sequential programming is the process of solving a problem in a chain, one problem at a time by CPU. Only one thing happens a a time. Such program which performs only one specified problem at a time in a chain in called a sequential programming.
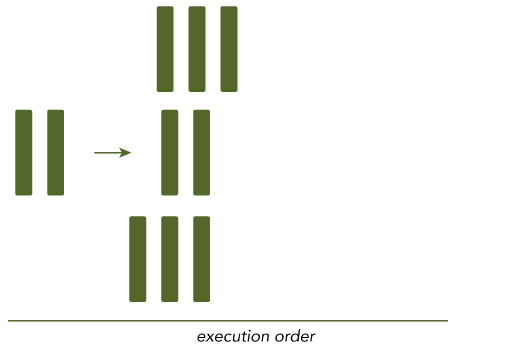
Program that can be broken down into pieces and are executed by multiple core at once to achieve the result is called parallel computing.
Parallelism
There are 2 types of parallelism:
- Task parallelism: When there are many tasks or functions that can be operated independently and largely in parallel focusing on distributing functions across multiple cores.
- Data parallelism: When there are many data items that can be operated on at the same time focusing on distributing the data across multiple cores.
CUDA programming is suited to address problems that can be expressed as data-parallel computations. Since my goal is CUDA programming, I will be focusing more on the data-parallel computations.
The initial step in designing a data parallel program is to distribute or partition the data across multiple threads where each thread will be working on a portion of data. There are 2 approaches to partitioning data:
- Block Partitioning: Block partitioning is often used when the computational load is distributed homogeneously over a regular data structure, such as Cartesian grid. It assigns block of size r of the global vector to the processes.
- Cyclic Partitioning: The cyclic distribution (AKA wrapped or scattered decomposition) is commonly used to improve load balance when the computational load is distributed in homogeneously over a regular data structure. It assigns consecutive entries of the global vector to successive processes.
If you want to learn about partitioning in more detail then visit IBM page.
Computer Architecture
The most common classification is Flynn’s Taxonomy which classifies architecture into four different types according to data flow through cores:
- Single Instruction Single Data (SISD)
- Single Instruction Multiple Data (SIMD)
- Multiple Instruction Single Data (MISD)
- Multiple Instruction Multiple Data (MIMD)
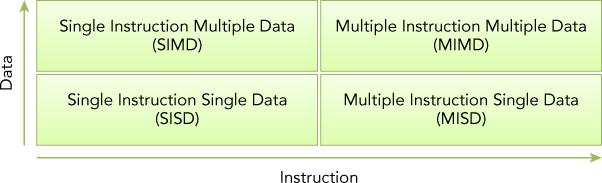
SISD: It refers to the traditional computer containing only one core in the CPU. Only 1 instruction can be processed at a time.
SIMD: It refers to parallel architecture where there are multiple cores in the CPU. All cores execute the same instruction which makes it run parallely. The biggest advantage of this architecture is you can write sequential code yet run it parallely.
MISD: It is unpopular architecture due to the fact that each core operates on the same data stream via separate instruction streams.
MIMD: It refers to parallel architecture where multiple cores operates on multiple data streams i.e. each executing independent instructions.
Heterogeneous Computing
CPUs and GPUs are discrete processing components connected via PCI-Express bus within single compute node. A GPU is not a standalone platform but rather a co-processor to the CPU. So, GPU must operate in conjunction with the CPU based host through a PCI-Express bus. This is the reason why CPU is called host and GPU is called device in GPU computation world.
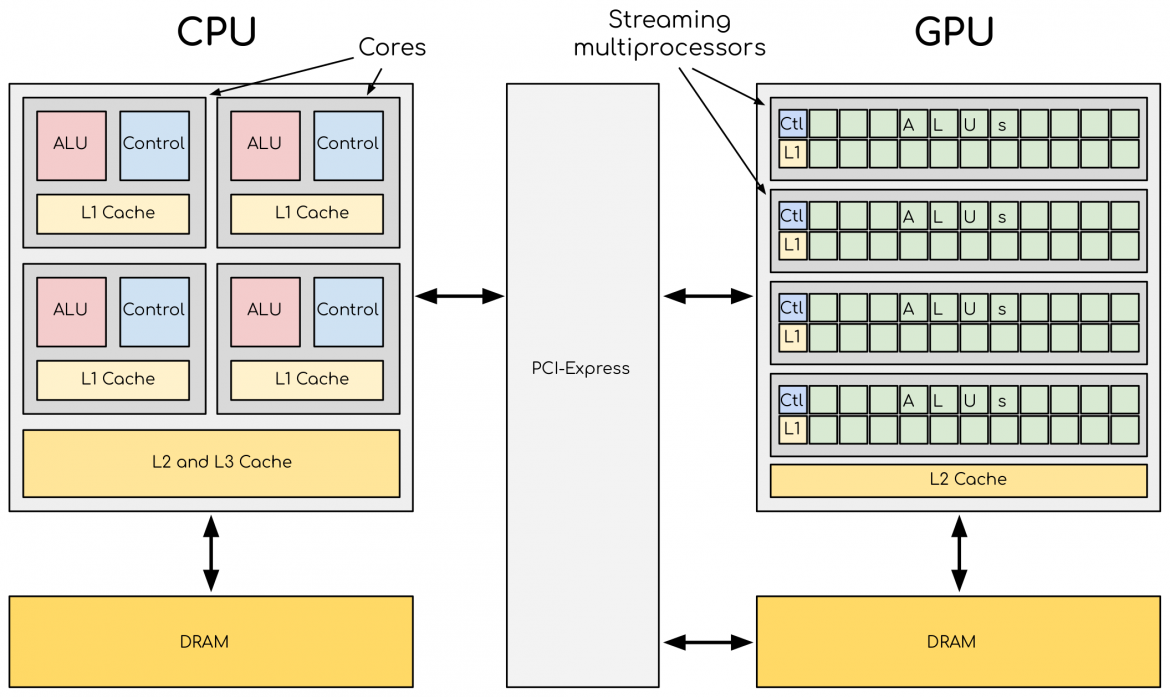
A heterogeneous application consists of two parts:
- Host code: It is the code that runs on CPU.
- Device code: It is the code that runs on GPU.
The application running on heterogeneous architecture is initialized by CPU & typically runs on GPU. CPU is responsible for managing the environment, code and data for the device before loading compute intensive task on the GPU. When the task is handed over to physically separate from CPU in order to accelerate compute intensive tasks of the application then it is called hardware accelerator. GPUs are the most common example of hardware accelerator. CPU computing is good for control-intensive task and GPU is good at data-parallel computation-intensive tasks. When CPUs are complimented by GPUs then it makes a powerful combination.
If a problem has a small data size, sophisticated control logic and/or low-level parallelism, the CPU is good choice due to it’s ability to handle complex logic and instruction level parallelism. If the problem needs processing a huge amount of data and exhibits massive data parallelism then GPU is the right choice due to the presence of large number of programmable cores which can support multi-threading. For optimal performance, you should run sequential portion in CPU and compute intensive portion in GPU.
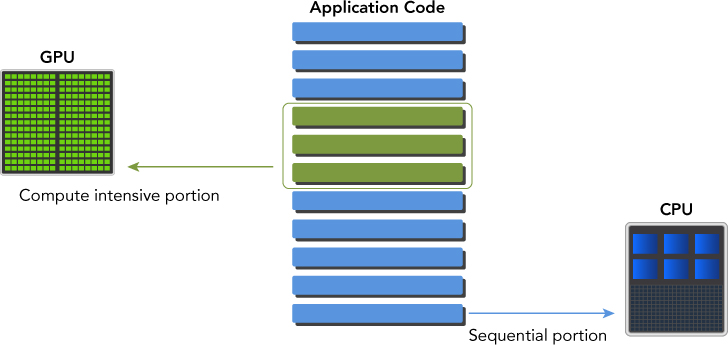
To support this type of programming NVIDIA created a new programming model i.e. Compute Unified Device Architecture (CUDA).
CUDA For Heterogeneous Computing
CUDA is a general purpose parallel programming model that leverages the parallel compute engine in NVIDIA GPUs to solve complex computational problems in a more efficient way.
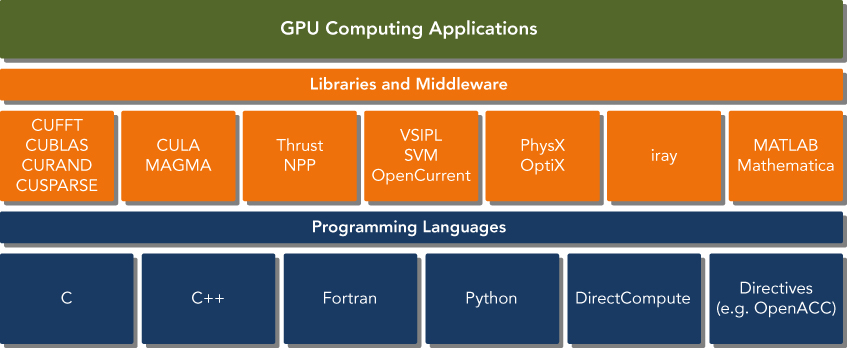
CUDA supports many low level languages such as C/C++ along with high level languages like Python. So, it really makes computational fast. I will be focusing on CUDA C programming as it gives me more control over the CPU.
Cuda C is an extension of standard ANSI C language with a language extension to enable heterogeneous programming along with APIs to manage devices, memory, etc. It is also a scalable programming model that enables programs to transparently scale their parallelism to GPUs varying on the cores present on the device.
There are 2 API levels for managing the GPU device and organizing threads:
- CUDA Driver API
- CUDA Runtime API
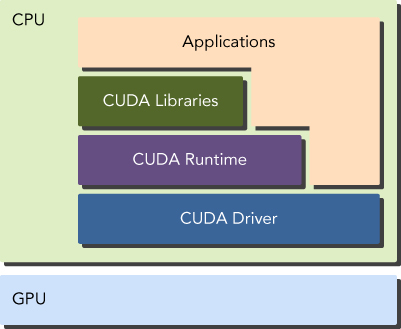
The driver API is the low-level API which provides more control over how GPU device is used but it is hard to program. The runtime API is high-level implementation on top of driver API which makes interacting with GPU much easier. In-short runtime API is just an abstraction layer implemented on top of driver API; Each function of runtime API is ultimately broken down into more basic operations to the driver API.
There is also no noticeable performance difference between runtime and driver APIs. The two APIs are mutually exclusive, you can only use one; it is not possible to mix both of them.
The CUDA program consists of a mixture of the 2 parts:
- Host code: Running on the CPU
- Device code: Running on the GPU
The nvcc compiler (CUDA compiler) separates the device code from the host code during the compilation process. The host code is C code and is compiled with C compiler. The device code written using CUDA C extended with keywords for labeling data-parallel functions called kernels are further compiled using nvcc. During the linking stage, CUDA runtime libraries are added for kernel procedure calls and explicit GPU device manipulation.
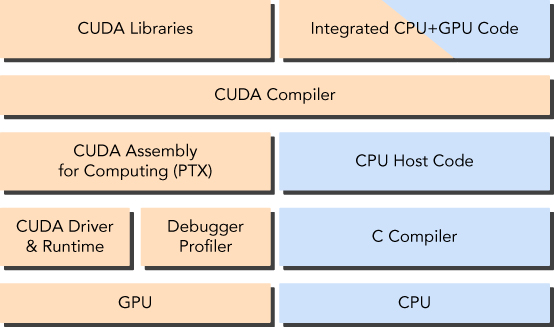
nvcc is a CUDA compiler. It is recommended to use Linux system to run cuda core. You can obviously google how to install CUDA or the best way is using the suggestion given by the terminal. Just type nvcc –version. If it gives a version then nvccc compiler is already present and if it isn’t present then it will suggest you a command to install it.
First GPU program, Hello World!
Create a codefile with extension of .cu. Then write code in that file and use nvcc compiler to compile and run the code.
Simple Hello world program using C:
#include <stdio.h>
int main(void) {
printf("Hello, World!\n");
return 0;
}
Result:

Hello world in CUDA
#include <stdio.h>
__global__ void helloGPU(void) {
printf("Hello, World! From GPU\n");
}
int main(void) {
printf("Hello, World! From CPU\n");
helloGPU<<<1, 10>>>();
cudaDeviceReset();
return 0;
}
Result:
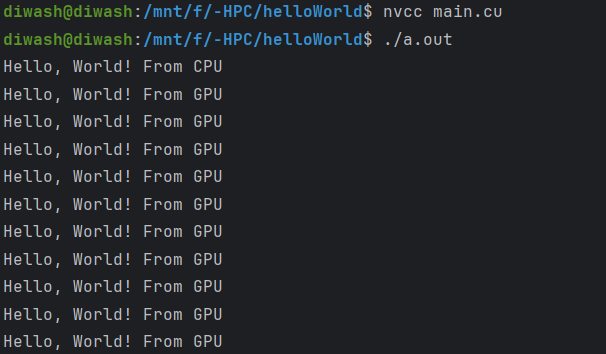
Congratulations on your first CUDA code. Try to learn how the code works on your own! It is just a Hello World program, no rocket science!
References
J. Cheng, M. Grossman, T. McKercher, and B. Chapman, Professional CUDA C Programming. 2014. [Online]. Available: https://learning.oreilly.com/library/view/professional-cuda-c/9781118739310/
“Parallel Engineering and Scientific Subroutine Library 5.5.” https://www.ibm.com/docs/en/pessl/5.5?topic=types-data-distribution-techniques